5.5. Tools and classes¶
Contents
5.5.1. Classes¶
This module provides the Base class for PSDs
-
class
Spectrum(data, data_y=None, sampling=1.0, detrend=None, scale_by_freq=True, NFFT=None)[source]¶ Base class for all Spectrum classes
All PSD classes should inherits from this class to store common attributes such as the input data or sampling frequency. An instance is created as follows:
>>> p = Spectrum(data, sampling=1024) >>> p.data >>> p.sampling
The input parameters are:
Parameters: - data (array) – input data (list or numpy.array)
- data_y (array) – input data required to perform cross-PSD only.
- sampling (float) – sampling frequency of the input
data - detrend (str) – detrend method ([None,’mean’]) to apply on the input data before
computing the PSD. See
detrend. - scale_by_freq (bool) – divide the final PSD by
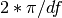
- NFFT (int) – total length of the final data sets (padded with zero if needed; default is 4096)
The input parameters are available as attributes. Additional attributes such as
N(the data length),df(the frequency step are set (see constructor documentation for a complete list).Warning
Spectrumdoes not compute the PSD estimate.You can populate manually the
psdattribute but you should respect the following convention:- if the input data is real, the PSD is assumed to be one-sided (odd length)
- if the input data is complex, the PSD is assumed to be two-sided (even length).
When
psdis set,sidesis reset to its default value,NFFTanddfare updated.Spectrum instances have plotting utilities like
plot()that take care of plotting the PSD versus the appropriate frequency range (based onsampling,NFFTandsides)Note
the modification of some attributes (e.g., NFFT), makes the PSD obsolete. In such cases, the PSD must be re-computed before using
plot()again.At any time, you can get general information about the Spectrum instance:
>>> p = Spectrum(marple_data) >>> print(p) Spectrum summary Data length is 64 PSD not yet computed Sampling 1.0 freq resolution 0.015625 datatype is complex sides is twosided scal_by_freq is True
Constructor
Attributes:
From the input parameters, the following attributes are set:
The following read-only attributes are set during the initialisation:
And finally, additional read-write attributes are available:
-
NFFT¶ Getter/Setter to the NFFT attribute.
Parameters: NFFT – a user choice for setting
NFFT.- if None, the NFFT is set to
N, the data length. - if ‘nextpow2’, computes the next power of 2 greater than or equal to the data length.
- if a integer is provided, it must be positive
- if None, the NFFT is set to
-
data¶ Getter/Setter for the input data. If input is a list, it is cast into a numpy.array. Then,
N,dfanddatatypeare updated.
-
data_y¶ Getter/Setter to the Y-data
-
datatype¶ Getter to the datatype (‘real’ or ‘complex’).
datatypeis automatically updated when changing the data.
-
detrend¶ Getter/Setter to detrend:
- None: do not perform any detrend.
- ‘mean’: remove the mean value of each segment from each segment of the data.
- ‘long-mean’: remove the mean value from the data before splitting it into segments.
- ‘linear’: remove linear trend from each segment.
-
get_converted_psd(sides)[source]¶ This function returns the PSD in the sides format
Parameters: sides (str) – the PSD format in [‘onesided’, ‘twosided’, ‘centerdc’] Returns: the expected PSD. from spectrum import * p = pcovar(marple_data, 15) centerdc_psd = p.get_converted_psd('centerdc')
-
method¶ def __call__(self, *args, **kargs): # To be use with care. THis function is there just to help, it # does not populate the proper attribute except psd. if self.method is not None:
#return res
-
plot(filename=None, norm=False, ylim=None, sides=None, **kargs)[source]¶ a simple plotting routine to plot the PSD versus frequency.
Parameters: from spectrum import * p = Periodogram(marple_data) p.plot(norm=True, marker='o')
(Source code, png, hires.png, pdf)

-
power()[source]¶ Return the power contained in the PSD
if scale_by_freq is False, the power is:
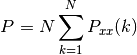
else, it is
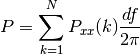
Todo
check these equations
-
psd¶ Getter/Setter to
psdParameters: psd (array) – the array must be in agreement with the onesided/twosided convention: if the data in real, the psd must be onesided. If the data is complex, the psd must be twosided. When you set this attribute, several attributes are set:
-
scale_by_freq¶ scale the PSD by
-
class
FourierSpectrum(data, sampling=1.0, window='hanning', NFFT=None, detrend=None, scale_by_freq=True, lag=-1)[source]¶ Spectrum based on Fourier transform.
This class inherits attributes and methods from
Spectrum. It is used by children classPeriodogram,pcorrelogramandWelchPSD estimates.The parameters are those used by
SpectrumParameters: - data (array) – Input data (list or numpy.array)
- data_y – input data required to perform cross-PSD only.
- sampling (float) – sampling frequency of the input
data - detrend (str) – detrend method ([None,’mean’]) to apply on the input
data before computing the PSD. See
detrend. - scale_by_freq (bool) – Divide the final PSD by
- NFFT (int) – total length of the data given to the FFT
In addition you need specific parameters such as:
Parameters: - window (str) – a tapering window. See
Window. - lag (int) – to be used by the
pcorrelogrammethods only.
This class has dedicated PSDs methods such as
speriodogram(), which are equivalent to children class such asPeriodogram.from spectrum import datasets from spectrum import FourierSpectrum s = FourierSpectrum(datasets.data_cosine(), lag=32, sampling=1024, NFFT=512) s.periodogram() s.plot(label='periodogram') #s.correlogram() s.plot(label='correlogram') from pylab import legend, xlim legend() xlim(0,512)
(Source code, png, hires.png, pdf)

Constructor
See the class documentation for the parameters.
Additional attributes to those inherited from
Spectrumare:-
lag¶ Getter/Setter used by the correlogram when autocorrelation estimates are required.
-
periodogram()[source]¶ An alias to
PeriodogramThe parameters are extracted from the attributes. Relevant attributes ares
window, attr:sampling, attr:NFFT, attr:scale_by_freq,detrend.from spectrum import datasets from spectrum import FourierSpectrum s = FourierSpectrum(datasets.data_cosine(), sampling=1024, NFFT=512) s.periodogram() s.plot()
(Source code, png, hires.png, pdf)

-
window¶ Tapering window to be applied
-
class
ParametricSpectrum(data, sampling=1.0, ar_order=None, ma_order=None, lag=-1, NFFT=None, detrend=None, scale_by_freq=True)[source]¶ Spectrum based on Fourier transform.
This class inherits attributes and methods from
Spectrum. It is used by children classPeriodogram,pcorrelogramandWelchPSD estimates. The parameters are those used bySpectrum.Parameters: - data (array) – Input data (list or numpy.array)
- sampling (float) – sampling frequency of the input
data - detrend (str) – detrend method ([None,’mean’]) to apply on the input
data before computing the PSD. See
detrend. - scale_by_freq (bool) – Divide the final PSD by
In addition you need specific parameters such as:
Parameters: - window (str) – a tapering window. See
Window. - lag (int) – to be used by the
pcorrelogrammethods only. - NFFT (int) – Total length of the data given to the FFT
This class has dedicated PSDs methods such as
periodogram(), which are equivalent to children class such asPeriodogram.from spectrum import datasets from spectrum import ParametricSpectrum data = datasets.data_cosine(N=1024) s = ParametricSpectrum(data, ar_order=4, ma_order=4, sampling=1024, NFFT=512, lag=10) #s.parma() #s.plot(sides='onesided') #s.plot(sides='twosided')
Constructor
See the class documentation for the parameters.
Additional attributes to those inherited from
Spectrum:-
ar¶
-
ar_order¶
-
ma¶
-
ma_order¶
-
reflection¶ self.reflection = None elif method == ‘aryule’:
from spectrum import aryule ar, v, coeff = aryule(self.data, self.ar_order) self.ar = ar self.rho = v self.reflection = coeff
-
rho¶
-
class
Range(N, sampling=1.0)[source]¶ A class to ease the creation of frequency ranges.
Given the length
Nof a data sample and a sampling frequencysampling, this class provides methods to generate frequency rangescenterdc(): frequency range from -sampling/2 up to sampling/2 (excluded),twosided(): frequency range from 0 up to sampling (excluded),onesided(): frequency range from 0 up to sampling (included).
Each method has a generator version:
>>> r = Range(10, sampling=1) >>> list(r.onesided_gen()) [0.0, 0.1, 0.2, 0.3, 0.4, 0.5] >>> r.onesided() [0.0, 0.1, 0.2, 0.3, 0.4, 0.5]
The frequency range length is
 for the onesided case
for the onesided case
 if
if 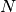 is odd), and for the twosided and
centerdc cases:
is odd), and for the twosided and
centerdc cases:>>> r.twosided() [0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9] >>> len(r.twosided()) 10 >>> len(r.centerdc()) 10 >>> len(r.onesided()) 5
Constructor
Parameters: - N (int) – the data length
- sampling (float) – sampling frequency of the input
data.
Attributes:
From the input parameters, read/write attributes are set:
Additionally, the following read-only attribute is available:
-
centerdc()[source]¶ Return the two-sided frequency range as a list (see
centerdc_gen()for details).
-
centerdc_gen()[source]¶ Return the centered frequency range as a generator.
>>> print(list(Range(8).centerdc_gen())) [-0.5, -0.375, -0.25, -0.125, 0.0, 0.125, 0.25, 0.375]
-
onesided()[source]¶ Return the one-sided frequency range as a list (see
onesided_gen()for details).
-
onesided_gen()[source]¶ Return the one-sided frequency range as a generator.
If
Nis even, the length is N/2 + 1. IfNis odd, the length is (N+1)/2.>>> print(list(Range(8).onesided())) [0.0, 0.125, 0.25, 0.375, 0.5] >>> print(list(Range(9).onesided())) [0.0, 0.1111, 0.2222, 0.3333, 0.4444]
-
twosided()[source]¶ Return the two-sided frequency range as a list (see
twosided_gen()for details).
5.5.2. Correlation¶
Correlation module
Provides two correlation functions. CORRELATION() is slower than
xcorr(). However, the output is as expected by some other functions.
Ultimately, it should be replaced by xcorr().
For real data, the behaviour of the 2 functions is identical. However, for complex data, xcorr returns a 2-sides correlation.
CORRELATION(x[, y, maxlags, norm]) |
Correlation function |
xcorr(x[, y, maxlags, norm]) |
Cross-correlation using numpy.correlate |
-
CORRELATION(x, y=None, maxlags=None, norm='unbiased')[source]¶ Correlation function
This function should give the same results as
xcorr()but it returns the positive lags only. Moreover the algorithm does not use FFT as compared to other algorithms.Parameters: - x (array) – first data array of length N
- y (array) – second data array of length N. If not specified, computes the autocorrelation.
- maxlags (int) – compute cross correlation between [0:maxlags] when maxlags is not specified, the range of lags is [0:maxlags].
- norm (str) –
normalisation in [‘biased’, ‘unbiased’, None, ‘coeff’]
- biased correlation=raw/N,
- unbiased correlation=raw/(N-|lag|)
- coeff correlation=raw/(rms(x).rms(y))/N
- None correlation=raw
Returns: - a numpy.array correlation sequence, r[1,N]
- a float for the zero-lag correlation, r[0]
The unbiased correlation has the form:
![\hat{r}_{xx} = \frac{1}{N-m}T \sum_{n=0}^{N-m-1} x[n+m]x^*[n] T](_images/math/995c60f95d47e60fa732d6c102c06d08c57ba71f.png)
The biased correlation differs by the front factor only:
![\check{r}_{xx} = \frac{1}{N}T \sum_{n=0}^{N-m-1} x[n+m]x^*[n] T](_images/math/20b43a9bfad04841164201ad1e058d876010a242.png)
with
 .
.>>> from spectrum import CORRELATION >>> x = [1,2,3,4,5] >>> res = CORRELATION(x,x, maxlags=0, norm='biased') >>> res[0] 11.0
Note
this function should be replaced by
xcorr().See also
-
xcorr(x, y=None, maxlags=None, norm='biased')[source]¶ Cross-correlation using numpy.correlate
Estimates the cross-correlation (and autocorrelation) sequence of a random process of length N. By default, there is no normalisation and the output sequence of the cross-correlation has a length 2*N+1.
Parameters: - x (array) – first data array of length N
- y (array) – second data array of length N. If not specified, computes the autocorrelation.
- maxlags (int) – compute cross correlation between [-maxlags:maxlags] when maxlags is not specified, the range of lags is [-N+1:N-1].
- option (str) – normalisation in [‘biased’, ‘unbiased’, None, ‘coeff’]
The true cross-correlation sequence is
![r_{xy}[m] = E(x[n+m].y^*[n]) = E(x[n].y^*[n-m])](_images/math/f5027ac89191159943d489d83202f5af551b66b6.png)
However, in practice, only a finite segment of one realization of the infinite-length random process is available.
The correlation is estimated using numpy.correlate(x,y,’full’). Normalisation is handled by this function using the following cases:
- ‘biased’: Biased estimate of the cross-correlation function
- ‘unbiased’: Unbiased estimate of the cross-correlation function
- ‘coeff’: Normalizes the sequence so the autocorrelations at zero
- lag is 1.0.
Returns: - a numpy.array containing the cross-correlation sequence (length 2*N-1)
- lags vector
Note
If x and y are not the same length, the shorter vector is zero-padded to the length of the longer vector.
Examples
>>> from spectrum import xcorr >>> x = [1,2,3,4,5] >>> c, l = xcorr(x,x, maxlags=0, norm='biased') >>> c array([ 11.])
See also
5.5.3. Tools¶
Tools module
db2mag(xdb) |
Convert decibels (dB) to magnitude |
db2pow(xdb) |
Convert decibels (dB) to power |
mag2db(x) |
Convert magnitude to decibels (dB) |
nextpow2(x) |
returns the smallest power of two that is greater than or equal to the |
pow2db(x) |
returns the corresponding decibel (dB) value for a power value x. |
onesided_2_twosided(data) |
Convert a two-sided PSD to a one-sided PSD |
twosided_2_onesided(data) |
Convert a one-sided PSD to a twosided PSD |
centerdc_2_twosided(data) |
Convert a center-dc PSD to a twosided PSD |
twosided_2_centerdc(data) |
Convert a two-sided PSD to a center-dc PSD |
Code author: Thomas Cokelaer, 2011
-
cshift(data, offset)[source]¶ Circular shift to the right (within an array) by a given offset
Parameters: - data (array) – input data (list or numpy.array)
- offset (int) – shift the array with the offset
>>> from spectrum import cshift >>> cshift([0, 1, 2, 3, -2, -1], 2) array([-2, -1, 0, 1, 2, 3])
-
db2mag(xdb)[source]¶ Convert decibels (dB) to magnitude
>>> from spectrum import db2mag >>> db2mag(-20) 0.1
See also
-
db2pow(xdb)[source]¶ Convert decibels (dB) to power
>>> from spectrum import db2pow >>> p = db2pow(-10) >>> p 0.1
See also
-
fftshift(x)[source]¶ wrapper to numpy.fft.fftshift
>>> from spectrum import fftshift >>> x = [100, 2, 3, 4, 5] >>> fftshift(x) array([ 4, 5, 100, 2, 3])
-
mag2db(x)[source]¶ Convert magnitude to decibels (dB)
The relationship between magnitude and decibels is:
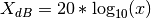
>>> from spectrum import mag2db >>> mag2db(0.1) -20.0
See also
-
nextpow2(x)[source]¶ returns the smallest power of two that is greater than or equal to the absolute value of x.
This function is useful for optimizing FFT operations, which are most efficient when sequence length is an exact power of two.
Example: >>> from spectrum import nextpow2 >>> x = [255, 256, 257] >>> nextpow2(x) array([8, 8, 9])
-
onesided_2_twosided(data)[source]¶ Convert a two-sided PSD to a one-sided PSD
In order to keep the power in the twosided PSD the same as in the onesided version, the twosided values are 2 times lower than the input data (except for the zero-lag and N-lag values).
>>> twosided_2_onesided([10, 4, 6, 8]) array([ 10., 2., 3., 3., 2., 8.])
-
pow2db(x)[source]¶ returns the corresponding decibel (dB) value for a power value x.
The relationship between power and decibels is:

>>> from spectrum import pow2db >>> x = pow2db(0.1) >>> x -10.0
-
twosided(data)[source]¶ return a twosided vector with non-duplication of the first element
>>> from spectrum import twosided >>> a = [1,2,3] >>> twosided(a) array([3, 2, 1, 2, 3])
-
twosided_2_onesided(data)[source]¶ Convert a one-sided PSD to a twosided PSD
In order to keep the power in the onesided PSD the same as in the twosided version, the onesided values are twice as much as in the input data (except for the zero-lag value).
>>> twosided_2_onesided([10, 2,3,3,2,8]) array([ 10., 4., 6., 8.])
5.5.4. datasets¶
The datasets module provides data sets to test the
Spectrum functionalities.
data_cosine([N, A, sampling, freq]) |
Return a noisy cosine at a given frequency. |
marple_data |
64-complex data length from Marple reference [Marple] |
TimeSeries(data[, sampling]) |
A simple Base Class for various data sets. |
Code author: Thomas Cokelaer 2011
| Reference: | [Marple] |
|---|
-
class
TimeSeries(data, sampling=1)[source]¶ A simple Base Class for various data sets.
>>> from spectrum import TimeSeries >>> data = [1, 2, 3, 4, 3, 2, 1, 0 ] >>> ts = TimeSeries(data, sampling=1) >>> ts.plot() >>> ts.dt 1.0
Parameters: - data (array) – input data (list or numpy.array)
- sampling – the sampling frequency of the data (default 1Hz)
-
data_cosine(N=1024, A=0.1, sampling=1024.0, freq=200)[source]¶ Return a noisy cosine at a given frequency.
Parameters: - N – the final data size
- A – the strength of the noise
- sampling (float) – sampling frequency of the input
data. - freq (float) – the frequency
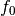 of the cosine.
of the cosine.
![x[t] = cos(2\pi t * f_0) + A w[t]](_images/math/5eabfa7aa74916fa5c27e9003935ec8c574ff255.png)
where w[t] is a white noise of variance 1.
>>> from spectrum import data_cosine >>> a = data_cosine(N=1024, sampling=1024, A=0.5, freq=100)
-
dolphin_filename= '/home/docs/checkouts/readthedocs.org/user_builds/pyspectrum/conda/stable/lib/python2.7/site-packages/spectrum-0.7.2-py2.7-linux-x86_64.egg/spectrum/data/DOLPHINS.wav'¶ filename of a WAV data file 150,000 data points
-
marple_data= [(1.349839091+2.011167288j), (-2.117270231+0.817693591j), (-1.786421657-1.291698933j), (1.162236333-1.482598066j), (1.641072035+0.372950256j), (0.072213709+1.828492761j), (-1.564284801+0.824533045j), (-1.080565453-1.869776845j), (0.92712909-1.743406534j), (1.891979456+0.972347319j), (-0.105391249+1.602209687j), (-1.618367076+0.63751328j), (-0.945704579-1.079569221j), (1.135566235-1.692269921j), (1.855816245+0.986030221j), (-1.032083511+1.414613724j), (-1.571600199+0.089229003j), (-0.243143231-1.444692016j), (0.838980973-0.985756695j), (1.516003132+0.928058863j), (0.257979959+1.170676708j), (-2.057927608+0.343388647j), (-0.578682184-1.441192508j), (1.584011555-1.011150956j), (0.614114344+1.508176208j), (-0.710567117+1.130144477j), (-1.100205779-0.584209621j), (0.150702029-1.217450142j), (0.748856127-0.804411888j), (0.795235813+1.114466429j), (-0.071512341+1.017092347j), (-1.732939839-0.283070654j), (0.404945314-0.78170836j), (1.293794155-0.352723092j), (-0.119905084+0.905150294j), (-0.522588372+0.437393665j), (-0.974838495-0.670074046j), (0.275279552-0.509659231j), (0.854210198-0.008278057j), (0.289598197+0.50623399j), (-0.283553183+0.250371397j), (-0.359602571-0.135261074j), (0.102775671-0.466086507j), (-0.00972265+0.030377999j), (0.185930878+0.8088696j), (-0.243692726-0.200126961j), (-0.270986766-0.460243553j), (0.399368525+0.249096692j), (-0.250714004-0.36299023j), (0.419116348-0.389185309j), (-0.050458215+0.702862442j), (-0.395043731+0.140808776j), (0.746575892-0.126762003j), (-0.55907619+0.523169816j), (-0.34438926-0.913451135j), (0.733228028-0.006237417j), (-0.480273813+0.509469569j), (0.033316225+0.087501869j), (-0.32122913-0.254548967j), (-0.063007891-0.499800682j), (1.239739418-0.013479125j), (0.083303742+0.673984587j), (-0.762731433+0.40897125j), (-0.895898521-0.364855707j)]¶ 64-complex data length from Marple reference [Marple]
-
randn(d0, d1, ..., dn)¶ Return a sample (or samples) from the “standard normal” distribution.
If positive, int_like or int-convertible arguments are provided, randn generates an array of shape
(d0, d1, ..., dn), filled with random floats sampled from a univariate “normal” (Gaussian) distribution of mean 0 and variance 1 (if any of the are
floats, they are first converted to integers by truncation). A single
float randomly sampled from the distribution is returned if no
argument is provided.
are
floats, they are first converted to integers by truncation). A single
float randomly sampled from the distribution is returned if no
argument is provided.This is a convenience function. If you want an interface that takes a tuple as the first argument, use numpy.random.standard_normal instead.
Parameters: d0, d1, …, dn : int, optional
The dimensions of the returned array, should be all positive. If no argument is given a single Python float is returned.
Returns: Z : ndarray or float
A
(d0, d1, ..., dn)-shaped array of floating-point samples from the standard normal distribution, or a single such float if no parameters were supplied.See also
random.standard_normal- Similar, but takes a tuple as its argument.
Notes
For random samples from
 , use:
, use:sigma * np.random.randn(...) + muExamples
>>> np.random.randn() 2.1923875335537315 #random
Two-by-four array of samples from N(3, 6.25):
>>> 2.5 * np.random.randn(2, 4) + 3 array([[-4.49401501, 4.00950034, -1.81814867, 7.29718677], #random [ 0.39924804, 4.68456316, 4.99394529, 4.84057254]]) #random
5.5.5. Linear Algebra Tools¶
5.5.5.1. cholesky¶
Cholesky methods
CHOLESKY(A, B[, method]) |
Solve linear system AX=B using CHOLESKY method. |
Code author: Thomas Cokelaer, 2011
-
CHOLESKY(A, B, method='scipy')[source]¶ Solve linear system AX=B using CHOLESKY method.
Parameters: - A – an input Hermitian matrix
- B – an array
- method (str) –
a choice of method in [numpy, scipy, numpy_solver]
- numpy_solver relies entirely on numpy.solver (no cholesky decomposition)
- numpy relies on the numpy.linalg.cholesky for the decomposition and numpy.linalg.solve for the inversion.
- scipy uses scipy.linalg.cholesky for the decomposition and scipy.linalg.cho_solve for the inversion.
Description
When a matrix is square and Hermitian (symmetric with lower part being the complex conjugate of the upper one), then the usual triangular factorization takes on the special form:

where
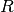 is a lower triangular matrix with nonzero real principal
diagonal element. The input matrix can be made of complex data. Then, the
inversion to find
is a lower triangular matrix with nonzero real principal
diagonal element. The input matrix can be made of complex data. Then, the
inversion to find 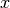 is made as follows:
is made as follows: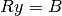
and

>>> import numpy >>> from spectrum import CHOLESKY >>> A = numpy.array([[ 2.0+0.j , 0.5-0.5j, -0.2+0.1j], ... [ 0.5+0.5j, 1.0+0.j , 0.3-0.2j], ... [-0.2-0.1j, 0.3+0.2j, 0.5+0.j ]]) >>> B = numpy.array([ 1.0+3.j , 2.0-1.j , 0.5+0.8j]) >>> CHOLESKY(A, B) array([ 0.95945946+5.25675676j, 4.41891892-7.04054054j, -5.13513514+6.35135135j])
5.5.5.2. eigen¶
-
MINEIGVAL(T0, T, TOL)[source]¶ Finds the minimum eigenvalue of a Hermitian Toeplitz matrix
The classical power method is used together with a fast Toeplitz equation solution routine. The eigenvector is normalized to unit length.
Parameters: - T0 – Scalar corresponding to real matrix element t(0)
- T – Array of M complex matrix elements t(1),…,t(M) C from the left column of the Toeplitz matrix
- TOL – Real scalar tolerance; routine exits when [ EVAL(k) - EVAL(k-1) ]/EVAL(k-1) < TOL , where the index k denotes the iteration number.
Returns: - EVAL - Real scalar denoting the minimum eigenvalue of matrix
- EVEC - Array of M complex eigenvector elements associated
Note
- External array T must be dimensioned >= M
- array EVEC must be >= M+1
- Internal array E must be dimensioned >= M+1 .
- dependencies
5.5.5.3. levinson¶
Levinson module
LEVINSON(r[, order, allow_singularity]) |
Levinson-Durbin recursion. |
Code author: Thomas Cokelaer, 2011
-
LEVINSON(r, order=None, allow_singularity=False)[source]¶ Levinson-Durbin recursion.
Find the coefficients of a length(r)-1 order autoregressive linear process
Parameters: - r – autocorrelation sequence of length N + 1 (first element being the zero-lag autocorrelation)
- order – requested order of the autoregressive coefficients. default is N.
- allow_singularity – false by default. Other implementations may be True (e.g., octave)
Returns: - the N+1 autoregressive coefficients

- the prediction errors
- the N reflections coefficients values
This algorithm solves the set of complex linear simultaneous equations using Levinson algorithm.
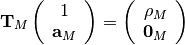
where
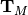 is a Hermitian Toeplitz matrix with elements
is a Hermitian Toeplitz matrix with elements
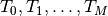 .
.Note
Solving this equations by Gaussian elimination would require
 operations whereas the levinson algorithm
requires
operations whereas the levinson algorithm
requires 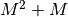 additions and multiplications.
additions and multiplications.This is equivalent to solve the following symmetric Toeplitz system of linear equations
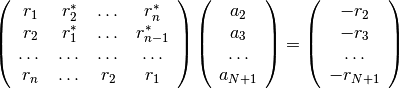
where
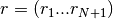 is the input autocorrelation vector, and
is the input autocorrelation vector, and
 denotes the complex conjugate of
denotes the complex conjugate of  . The input r is typically
a vector of autocorrelation coefficients where lag 0 is the first
element
. The input r is typically
a vector of autocorrelation coefficients where lag 0 is the first
element  .
.>>> import numpy; from spectrum import LEVINSON >>> T = numpy.array([3., -2+0.5j, .7-1j]) >>> a, e, k = LEVINSON(T)
-
rlevinson(a, efinal)[source]¶ computes the autocorrelation coefficients, R based on the prediction polynomial A and the final prediction error Efinal, using the stepdown algorithm.
Works for real or complex data
Parameters: - a –
- efinal –
Returns: - R, the autocorrelation
- U prediction coefficient
- kr reflection coefficients
- e errors
A should be a minimum phase polynomial and A(1) is assumed to be unity.
Returns: - (P+1) by (P+1) upper triangular matrix, U,
- that holds the i’th order prediction polynomials
Ai, i=1:P, where P is the order of the input
polynomial, A.[ 1 a1(1)* a2(2)* ….. aP(P) * ] [ 0 1 a2(1)* ….. aP(P-1)* ]
- U = [ ……………………………]
- [ 0 0 0 ….. 1 ]
from which the i’th order prediction polynomial can be extracted using Ai=U(i+1:-1:1,i+1)’. The first row of U contains the conjugates of the reflection coefficients, and the K’s may be extracted using, K=conj(U(1,2:end)).
Todo
remove the conjugate when data is real data, clean up the code test and doc.
5.5.5.4. toeplitz¶
Toeplitz module
These functions are not yet used by other functions, which explains the lack of documentation, test, examples.
Nevertheless, they can be used for production.
HERMTOEP(T0, T, Z) |
solve Tx=Z by a variation of Levinson algorithm where T |
Code author: Thomas Cokelaer, 2011
5.5.5.5. linalg¶
Linear algebra tools
csvd(A) |
SVD decomposition using numpy.linalg.svd |
corrmtx(x_input, m[, method]) |
Correlation matrix |
pascal(n) |
Return Pascal matrix |
Code author: Thomas Cokelaer 2011
-
pascal(n)[source]¶ Return Pascal matrix
Parameters: n (int) – size of the matrix >>> from spectrum import pascal >>> pascal(6) array([[ 1., 1., 1., 1., 1., 1.], [ 1., 2., 3., 4., 5., 6.], [ 1., 3., 6., 10., 15., 21.], [ 1., 4., 10., 20., 35., 56.], [ 1., 5., 15., 35., 70., 126.], [ 1., 6., 21., 56., 126., 252.]])
Todo
use the symmetric property to improve computational time if needed
-
csvd(A)[source]¶ SVD decomposition using numpy.linalg.svd
Parameters: A – a M by N matrix Returns: - U, a M by M matrix
- S the N eigen values
- V a N by N matrix
See
numpy.linalg.svd()for a detailed documentation.Should return the same as in [Marple] , CSVD routine.
U, S, V = numpy.linalg.svd(A) U, S, V = cvsd(A)
-
corrmtx(x_input, m, method='autocorrelation')[source]¶ Correlation matrix
This function is used by PSD estimator functions. It generates the correlation matrix from a correlation data set and a maximum lag.
Parameters: - x (array) – autocorrelation samples (1D)
- m (int) – the maximum lag
Depending on the choice of the method, the correlation matrix has different sizes, but the number of rows is always m+1.
Method can be :
- ‘autocorrelation’: (default) X is the (n+m)-by-(m+1) rectangular Toeplitz matrix derived using prewindowed and postwindowed data.
- ‘prewindowed’: X is the n-by-(m+1) rectangular Toeplitz matrix derived using prewindowed data only.
- ‘postwindowed’: X is the n-by-(m+1) rectangular Toeplitz matrix that derived using postwindowed data only.
- ‘covariance’: X is the (n-m)-by-(m+1) rectangular Toeplitz matrix derived using nonwindowed data.
- ‘modified’: X is the 2(n-m)-by-(m+1) modified rectangular Toeplitz matrix that generates an autocorrelation estimate for the length n data vector x, derived using forward and backward prediction error estimates.
Returns: - the autocorrelation matrix
- R, the (m+1)-by-(m+1) autocorrelation matrix estimate
R= X'*X.
Algorithm details:
The autocorrelation matrix is a
 rectangular Toeplilz
data matrix:
rectangular Toeplilz
data matrix: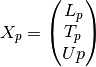
where the lower triangular
 matrix
matrix 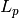 is
is![L_p =
\begin{pmatrix}
x[1] & \cdots & 0 & 0 \\
\vdots & \ddots & \vdots & \vdots \\
x[p] & \cdots & x[1] & 0
\end{pmatrix}](_images/math/1fe7c651857540d43c122fd093d4e904dd18457c.png)
where the rectangular
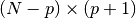 matrix
matrix 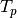 is
is![T_p =
\begin{pmatrix}
x[p+1] & \cdots & x[1] \\
\vdots & \ddots & \vdots \\
x[N-p] & \cdots & x[p+1] \\
\vdots & \ddots & \vdots \\
x[N] & \cdots & x[N-p]
\end{pmatrix}](_images/math/420cc632b111d7ad7c0f4b4aeabe487d57f3c9dd.png)
and where the upper triangular
matrix  is
is![U_p =
\begin{pmatrix}
0 & x[N] & \cdots & x[N-p+1] \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & x[N]
\end{pmatrix}](_images/math/182fa2820c22aaf4a64d9692b91b9d7247fcba99.png)
From this definition, the prewindowed matrix is
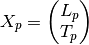
the postwindowed matrix is
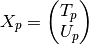
the covariance matrix is:

and the modified covariance matrix is:

5.5.5.6. Transfer function¶
Linear systems
-
tf2zp(b, a)[source]¶ Convert transfer function filter parameters to zero-pole-gain form
Find the zeros, poles, and gains of this continuous-time system:
Warning
b and a must have the same length.
from spectrum import tf2zp b = [2,3,0] a = [1, 0.4, 1] [z,p,k] = tf2zp(b,a) % Obtain zero-pole-gain form z = 1.5 0 p = -0.2000 + 0.9798i -0.2000 - 0.9798i k = 2
Parameters: - b – numerator
- a – denominator
- fill – If True, check that the length of a and b are the same. If not, create a copy of the shortest element and append zeros to it.
Returns: z (zeros), p (poles), g (gain)
Convert transfer function f(x)=sum(b*x^n)/sum(a*x^n) to zero-pole-gain form f(x)=g*prod(1-z*x)/prod(1-p*x)
Todo
See if tf2ss followed by ss2zp gives better results. These are available from the control system toolbox. Note that the control systems toolbox doesn’t bother, but instead uses
See also
scipy.signal.tf2zpk, which gives the same results but uses a different algorithm (z^-1 instead of z).
-
eqtflength(b, a)[source]¶ Given two list or arrays, pad with zeros the shortest array
Parameters: - b – list or array
- a – list or array
>>> from spectrum.transfer import eqtflength >>> a = [1,2] >>> b = [1,2,3,4] >>> a, b, = eqtflength(a,b)
-
ss2zpk(a, b, c, d, input=0)[source]¶ State-space representation to zero-pole-gain representation.
Parameters: - A – ndarray State-space representation of linear system.
- B – ndarray State-space representation of linear system.
- C – ndarray State-space representation of linear system.
- D – ndarray State-space representation of linear system.
- input (int) – optional For multiple-input systems, the input to use.
Returns: - z, p : sequence Zeros and poles.
- k : float System gain.
Note
wrapper of scipy function ss2zpk
-
tf2zpk(b, a)[source]¶ Return zero, pole, gain (z,p,k) representation from a numerator, denominator representation of a linear filter.
Convert zero-pole-gain filter parameters to transfer function form
Parameters: - b (ndarray) – numerator polynomial.
- a (ndarray) – numerator and denominator polynomials.
Returns: - z : ndarray Zeros of the transfer function.
- p : ndarray Poles of the transfer function.
- k : float System gain.
If some values of b are too close to 0, they are removed. In that case, a BadCoefficients warning is emitted.
>>> import scipy.signal >>> from spectrum.transfer import tf2zpk >>> [b, a] = scipy.signal.butter(3.,.4) >>> z, p ,k = tf2zpk(b,a)
See also
Note
wrapper of scipy function tf2zpk
-
zpk2ss(z, p, k)[source]¶ Zero-pole-gain representation to state-space representation
Parameters: - z,p (sequence) – Zeros and poles.
- k (float) – System gain.
Returns: - A, B, C, D : ndarray State-space matrices.
Note
wrapper of scipy function zpk2ss
-
zpk2tf(z, p, k)[source]¶ Return polynomial transfer function representation from zeros and poles
Parameters: - z (ndarray) – Zeros of the transfer function.
- p (ndarray) – Poles of the transfer function.
- k (float) – System gain.
Returns: b : ndarray Numerator polynomial. a : ndarray Numerator and denominator polynomials.
zpk2tf()forms transfer function polynomials from the zeros, poles, and gains of a system in factored form.zpk2tf(z,p,k) finds a rational transfer function
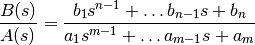
given a system in factored transfer function form
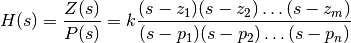
with p being the pole locations, and z the zero locations, with as many. The gains for each numerator transfer function are in vector k. The zeros and poles must be real or come in complex conjugate pairs. The polynomial denominator coefficients are returned in row vector a and the polynomial numerator coefficients are returned in matrix b, which has as many rows as there are columns of z.
Inf values can be used as place holders in z if some columns have fewer zeros than others.
Note
wrapper of scipy function zpk2tf
5.5.6. Waveforms¶
-
morlet(lb, ub, n)[source]¶ Generate the Morlet waveform
The Morlet waveform is defined as follows:
![w[x] = \cos{5x} \exp^{-x^2/2}](_images/math/be2c58bd08cdc13093ec7c9c929fa35d85fbf02f.png)
Parameters: - lb – lower bound
- ub – upper bound
- n (int) – waveform data samples
from spectrum import morlet from pylab import plot plot(morlet(0,10,100))
(Source code, png, hires.png, pdf)

-
chirp(t, f0=0.0, t1=1.0, f1=100.0, form='linear', phase=0)[source]¶ Evaluate a chirp signal at time t.
A chirp signal is a frequency swept cosine wave.
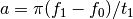
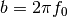
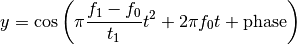
Parameters: - t (array) – times at which to evaluate the chirp signal
- f0 (float) – frequency at time t=0 (Hz)
- t1 (float) – time t1
- f1 (float) – frequency at time t=t1 (Hz)
- form (str) – shape of frequency sweep in [‘linear’, ‘quadratic’, ‘logarithmic’]
- phase (float) – phase shift at t=0
The parameter form can be:
- ‘linear’
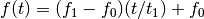
- ‘quadratic’

- ‘logarithmic’

Example:
from spectrum import chirp from pylab import linspace, plot t = linspace(0, 1, 1000) y = chirp(t, form='linear') plot(y) y = chirp(t, form='quadratic') plot(y, 'r')
(Source code, png, hires.png, pdf)




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
5.5.7. Linear prediction¶
Linear prediction tools
| References: | [Kay] |
|---|
-
ac2poly(data)[source]¶ Convert autocorrelation sequence to prediction polynomial
Parameters: data (array) – input data (list or numpy.array) Returns: - AR parameters
- noise variance
This is an alias to:
a, e, c = LEVINSON(data)
Example: >>> from spectrum import ac2poly >>> from numpy import array >>> r = [5, -2, 1.01] >>> ar, e = ac2poly(r) >>> ar array([ 1. , 0.38, -0.05]) >>> e 4.1895000000000007
-
poly2ac(poly, efinal)[source]¶ Convert prediction filter polynomial to autocorrelation sequence
Parameters: - poly (array) – the AR parameters
- efinal – an estimate of the final error
Returns: the autocorrelation sequence in complex format.
>>> from numpy import array >>> from spectrum import poly2ac >>> poly = [ 1. , 0.38 , -0.05] >>> efinal = 4.1895 >>> poly2ac(poly, efinal) array([ 5.00+0.j, -2.00+0.j, 1.01-0.j])
-
ac2rc(data)[source]¶ Convert autocorrelation sequence to reflection coefficients
Parameters: data – an autorrelation vector Returns: the reflection coefficient and data[0] This is an alias to:
a, e, c = LEVINSON(data) c, data[0]
-
rc2poly(kr, r0=None)[source]¶ convert reflection coefficients to prediction filter polynomial
Parameters: k – reflection coefficients
-
rc2ac(k, R0)[source]¶ Convert reflection coefficients to autocorrelation sequence.
Parameters: - k – reflection coefficients
- R0 – zero-lag autocorrelation
Returns: the autocorrelation sequence
-
is2rc(inv_sin)[source]¶ Convert inverse sine parameters to reflection coefficients.
Parameters: inv_sin – inverse sine parameters Returns: reflection coefficients Reference: J.R. Deller, J.G. Proakis, J.H.L. Hansen, “Discrete-Time Processing of Speech Signals”, Prentice Hall, Section 7.4.5.
-
rc2is(k)[source]¶ Convert reflection coefficients to inverse sine parameters.
Parameters: k – reflection coefficients Returns: inverse sine parameters - Reference: J.R. Deller, J.G. Proakis, J.H.L. Hansen, “Discrete-Time
- Processing of Speech Signals”, Prentice Hall, Section 7.4.5.
-
rc2lar(k)[source]¶ Convert reflection coefficients to log area ratios.
Parameters: k – reflection coefficients Returns: inverse sine parameters The log area ratio is defined by G = log((1+k)/(1-k)) , where the K parameter is the reflection coefficient.
References: [1] J. Makhoul, “Linear Prediction: A Tutorial Review,” Proc. IEEE, Vol.63, No.4, pp.561-580, Apr 1975.
-
lar2rc(g)[source]¶ Convert log area ratios to reflection coefficients.
Parameters: g – log area ratios Returns: the reflection coefficients References: [1] J. Makhoul, “Linear Prediction: A Tutorial Review,” Proc. IEEE, Vol.63, No.4, pp.561-580, Apr 1975.
-
poly2rc(a, efinal)[source]¶ Convert prediction filter polynomial to reflection coefficients
Parameters: - a – AR parameters
- efinal –
-
lsf2poly(lsf)[source]¶ Convert line spectral frequencies to prediction filter coefficients
returns a vector a containing the prediction filter coefficients from a vector lsf of line spectral frequencies.
>>> from spectrum import lsf2poly >>> lsf = [0.7842 , 1.5605 , 1.8776 , 1.8984, 2.3593] >>> a = lsf2poly(lsf)
# array([ 1.00000000e+00, 6.14837835e-01, 9.89884967e-01, # 9.31594056e-05, 3.13713832e-03, -8.12002261e-03 ])
See also
poly2lsf, rc2poly, ac2poly, rc2is
-
poly2lsf(a)[source]¶ Prediction polynomial to line spectral frequencies.
converts the prediction polynomial specified by A, into the corresponding line spectral frequencies, LSF. normalizes the prediction polynomial by A(1).
>>> from spectrum import poly2lsf >>> a = [1.0000, 0.6149, 0.9899, 0.0000 ,0.0031, -0.0082] >>> lsf = poly2lsf(a) >>> lsf = array([0.7842, 1.5605, 1.8776, 1.8984, 2.3593])
See also
lsf2poly, poly2rc, poly2qc, rc2is